Random Forest to Predict Random Forest Fires
Presented at the 2020 Women in Data Science Conference Philadelphia @ Penn

Featured on Wharton Stories and Knowledge@Wharton
In spring 2020, I presented along with my teammates, Melisa Lee and Zhun Yan Chang, at the Women in Data Science Conference in Philadelphia as the only undergraduates invited to speak.
Motivating the Project

In 2003, a fire broke out in the San Bernardino mountains. The fire, which is now known as Old Fire, resulted in over $1.2 billion in damages and the evacuation of over 80,000 people. My family was one of the families that had to be evacuated from our home. I was only 4 at the time, and I remember how terrifying it was to see pictures of the mountains on fire, lighting up the night. And we had to deal with the thought of leaving home without knowing if we would ever be able to go back.
In recent years, this problem has only gotten worse. In 2019, California declared the a state of emergency when over a dozen fires raged on, burning over 100,000 acres and causing 200,000 evacuations in late October, a time that is not usually considered as a fire-season month. As this problem only continues to become more serious, it is important for the Californian fire departments to be able to accurately identify high-risk areas in order to adequately prepare for and respond to wildfire disasters.
Asking the Question
In this project, our team seeks to analyze the factors which can predict the size of a discovered wildfire. Our analysis joins fire records with vegetation and climate data from the United States Department of Agriculture Forest Service to determine how these factors influence the size of a fire. Our objective is to build a predictive model using R that helps us identify the most at-risk areas for wildfires in California to inform decision making in the future and improve the safety for state residents.
Processing the Data
For the analysis, I joined two datasets to provide a full-picture for almost 115,000 fires in California from 2001-2015. The US Government Forest Research Data Archive included unique records for each fire while the ArcGIS REST by the US Department of Agriculture provided data on climate conditions that I could match on location to our fire records.
Department of Agriculture
Vegetation Fuel Type: likelihood of plant types to burn
Fire Return Interval: average period between fires
Wildfire Suppression Difficulty
Drought Index
Forest Research Data Archive
Fire Location: longitude and latitude
Fire Date
Time of Discovery
Suspected Cause: lighting, arson, structure, etc.
Reporting Agency

The initial steps involve collecting and cleaning data. Since high quality is fundamental to the entire project, we put immense efforts to aggregating a set from the 2 sources. This process itself took a majority of the time spent and involved writing scripts to scrape relevant data points such as vegetation fuel type and drought index. After we compiled our dataset, we cleaned and reformatted the data to ensure that each variable made intuitive sense in modeling the real world.
Exploring the Visualizations
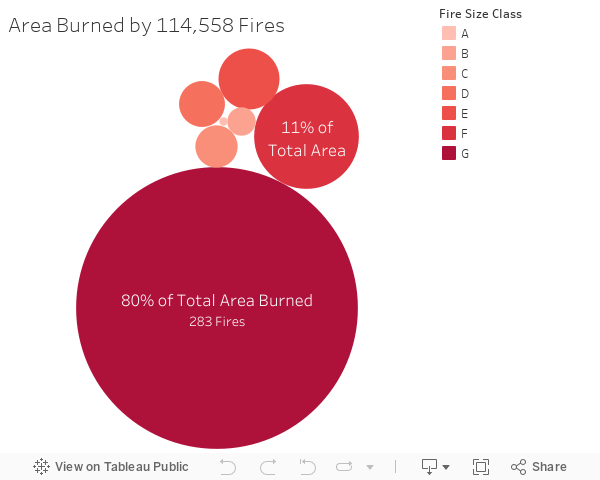
I noticed that a small amount of fires cause the most damage. Fires are categorized into 7 fires sizes based on acreage with A being the smallest and G being the largest. As we can see from the diagram, when we analyze over 100,000 fires from 15 years, over 80% of total area burned was caused by 280 fires. As a result, identifying the the factors that are most strongly correlated with fire size can be incredibly valuable in targeting which fires are likely to be the largest and therefore focus on minimizing the damage.
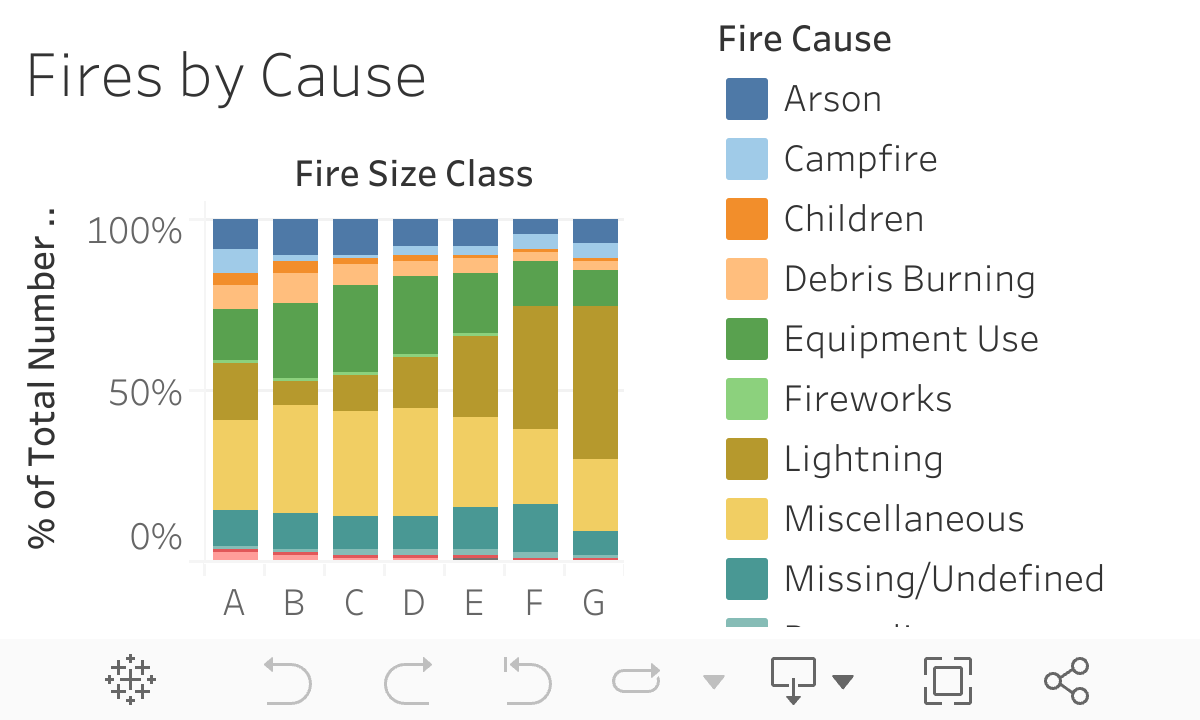
Keeping that in mind, I decided to break down fire size class and see if the causes of the fire differ based on its size. In the graph above, we can see that there is a clear relationship between the size and cause. In particular, lightning accounts for almost half of the larger fires that cause a disproportionate amount of destruction.
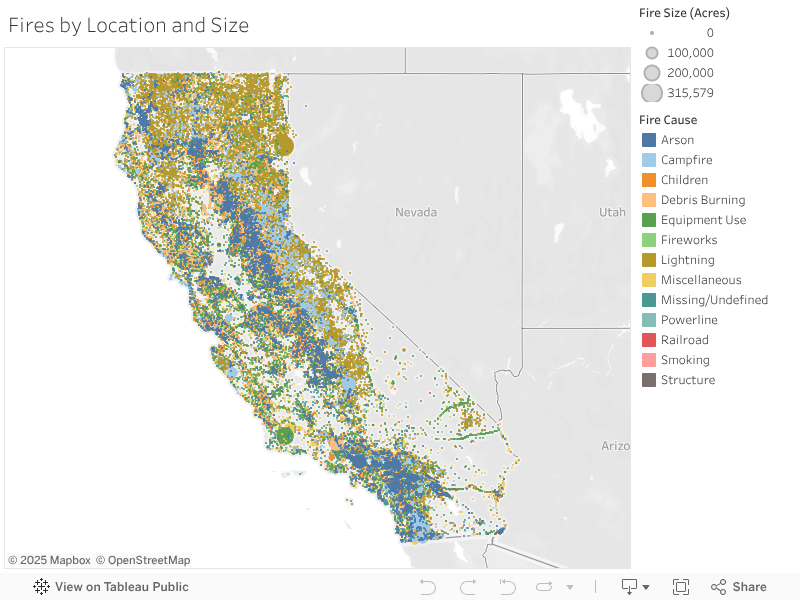

When we look at the location of the fires, we see that several patterns begin to appear, especially when we compare it to a simple vegetation map of California. For example, there are close to no fires in the bottom right corner of the state, which corresponds with the desert where there is little vegetation to burn. We can also look at the blue fires, which represent arson. These seem to line the California valley and concentrate near the coastlines. This makes sense since this is where the people live. And in order to commit arson, you need people.
Now let’s go back and look at the lightning fires from before. If you click on the lightning fires square on the graph above, you can get a view of the distribution of lightning fires themselves. When we compare this with our vegetation graph, we see that it covers the same area as conifer-type vegetation.
Modeling the Data
Since we wanted our analysis to aid in future prevention efforts, it was important for us to model the data in a way that would be accessible to the general public. As a result, our first model was a simple linear regression which we then used LASSO for variable selection. However, many of the factors which we believed were most influential in determining fire size were categorical, such as: cause of fire and vegetation type. And linear regressions are lacking when it comes to capturing the effects of different qualitative features. Thus, we also ran a random forest model. Between these two, there were a number of features that ended being highly significant.
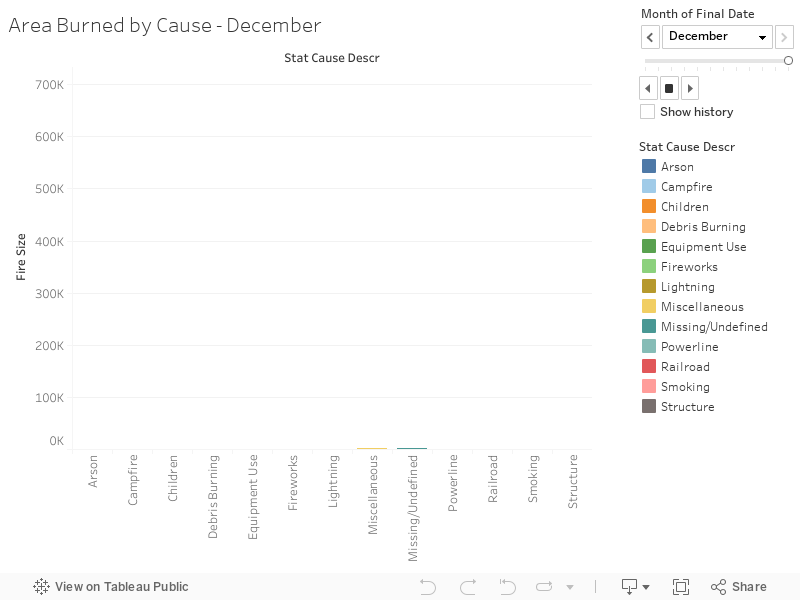
Press the play button on the top right of the graph above to see the monthly changes.
Unsurprisingly, we see that most of the area burned happens during California’s fire season, between July and September. But this graph also shows us that the jumps we see in area burned largely depend on the cause of the fire. So while the area burned from arson stays constant throughout the year, we see a huge jump in the destructiveness of lightning fires in the summer months. This tells us that we should target lightning fires for prevention.
Through our formal analysis we found that one significant vegetation type that causes bigger wildfire is timber litter, which is the layer of dead branches or dead woody plants that sometimes line the forest floor. When we conducted further research, we learned that timber litter burns fast and spreads faster. And in line with our story, areas with high amounts of timber litter also have high likelihoods of lightning fires.
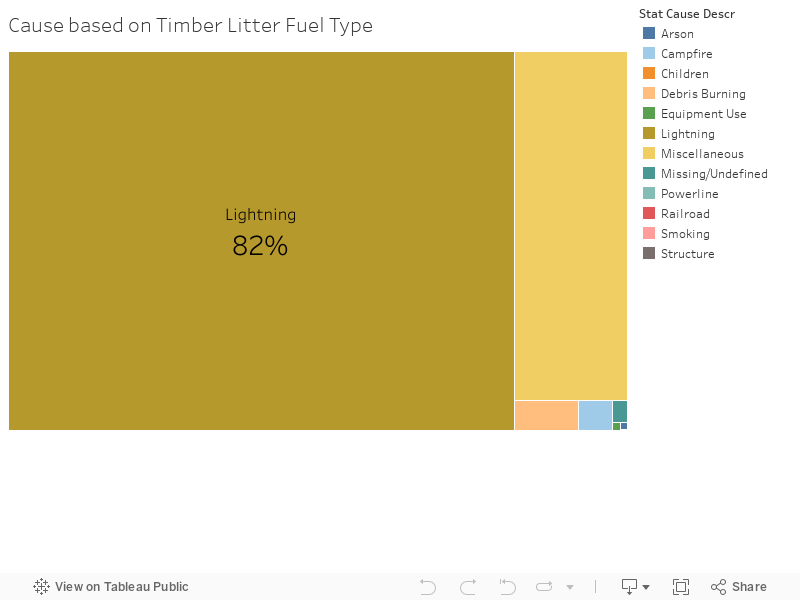
Recommending a Solution
Throughout our analysis, one predictor that consistently appeared was lighting. Although at first glance, this seems like an uncontrollable natural phenomenon, there are still many factors we can control to prevent large wildfires. An actionable step that the government can take is using controlled burning to prevent the buildup of timber litter, which serve as fuel for larger fires. This process involves starting small, highly scrutinized fires that only burn away litter without damaging trees. It mimics the natural way in which forests maintain ecological health and returns nutrients back to the soil. Therefore, by using controlled burning before the summer fire season when lightning is more likely to hit, we can prevent large wildfires from destroying the homes and livelihoods of people in California.

Special thanks to my teammates, Melisa Lee and Zhun Yan Chang, who spent countless hours in the computer lab scraping, cleaning, and modeling the data; our project mentor, Dr. Linda Zhao, who always asked the right questions and helped us understand our own story; and Analytics@Wharton, for giving us a chance to share our project.